用 PostHog 监控你的 AI Agent:从调用追踪到成本核算
最近在公司做一个 Agent 项目,跑通了基本流程之后,遇到一个很现实的问题:线上用户反馈"回答不对"或者"响应太慢",我根本没法排查。日志里只有零散的 print,完全看不出一次对话里到底调了几次模型、每次花了多久、tool call 有没有报错。
我需要一个能看清 Agent 每一步在干什么的监控工具。
PostHog 的 LLM Analytics
偶然看到 PostHog 出了 LLM observability 的功能,抱着试试的心态接了一下,发现这东西是真的好用。
PostHog 把 AI Agent 的监控拆成了三层:
- Trace — 一次完整的用户对话
- Generation — 每一次 LLM API 调用
- Span — 每一次 tool 执行
这个层级结构跟 Agent 的实际运行方式完全对应。一个用户提问进来,Agent 可能调 3 次模型、执行 5 个 tool,这些全部串在一个 trace 下面,一目了然。
接入过程
接入非常简单,核心就是在几个关键节点上报事件。
初始化一个 client:
from posthog import Posthog
client = Posthog(
api_key="phc_xxx",
host="https://us.i.posthog.com"
)
每次 LLM 调用完成后,上报一个 $ai_generation 事件:
client.capture(
distinct_id=user_id,
event="$ai_generation",
properties={
"$ai_model": "gpt-4o",
"$ai_provider": "openai",
"$ai_input": messages,
"$ai_output_choices": response.choices,
"$ai_input_tokens": usage.prompt_tokens,
"$ai_output_tokens": usage.completion_tokens,
"$ai_cache_read_input_tokens": cached_tokens, # 别漏了这个,后面会讲
"$ai_latency": 1.23,
"$ai_trace_id": trace_id,
"$ai_tools": tools,
}
)
tool 执行完上报一个 $ai_span:
client.capture(
distinct_id=user_id,
event="$ai_span",
properties={
"$ai_span_name": "get_weather",
"$ai_input": tool_args,
"$ai_output": tool_result,
"$ai_latency": 0.45,
"$ai_trace_id": trace_id,
}
)
整个对话结束后上报一个 $ai_trace,把整条链路收口。
我在项目里的做法是把这些上报逻辑封装在 LLM provider 的基类里,所有模型调用自动上报,不需要业务代码里到处埋点。tool 执行的上报放在 agent loop 的回调里,也是自动的。
实际效果
接进去之后,打开 PostHog 的 LLM Analytics 面板,能看到所有 trace 的列表:
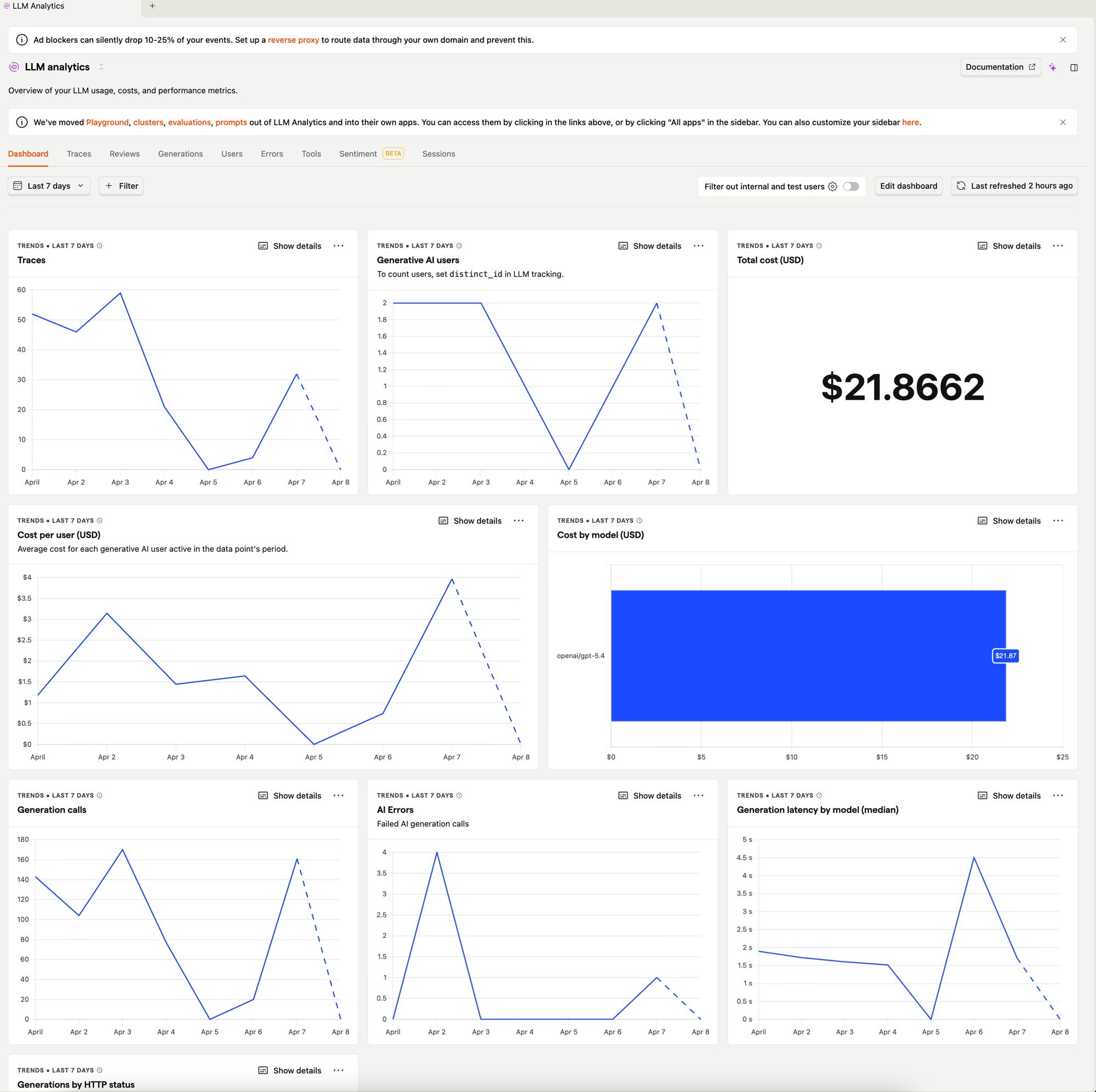
每一行就是一次用户对话,能看到总耗时、token 用量、是否报错。
点进去某一条 trace,能看到完整的调用链:
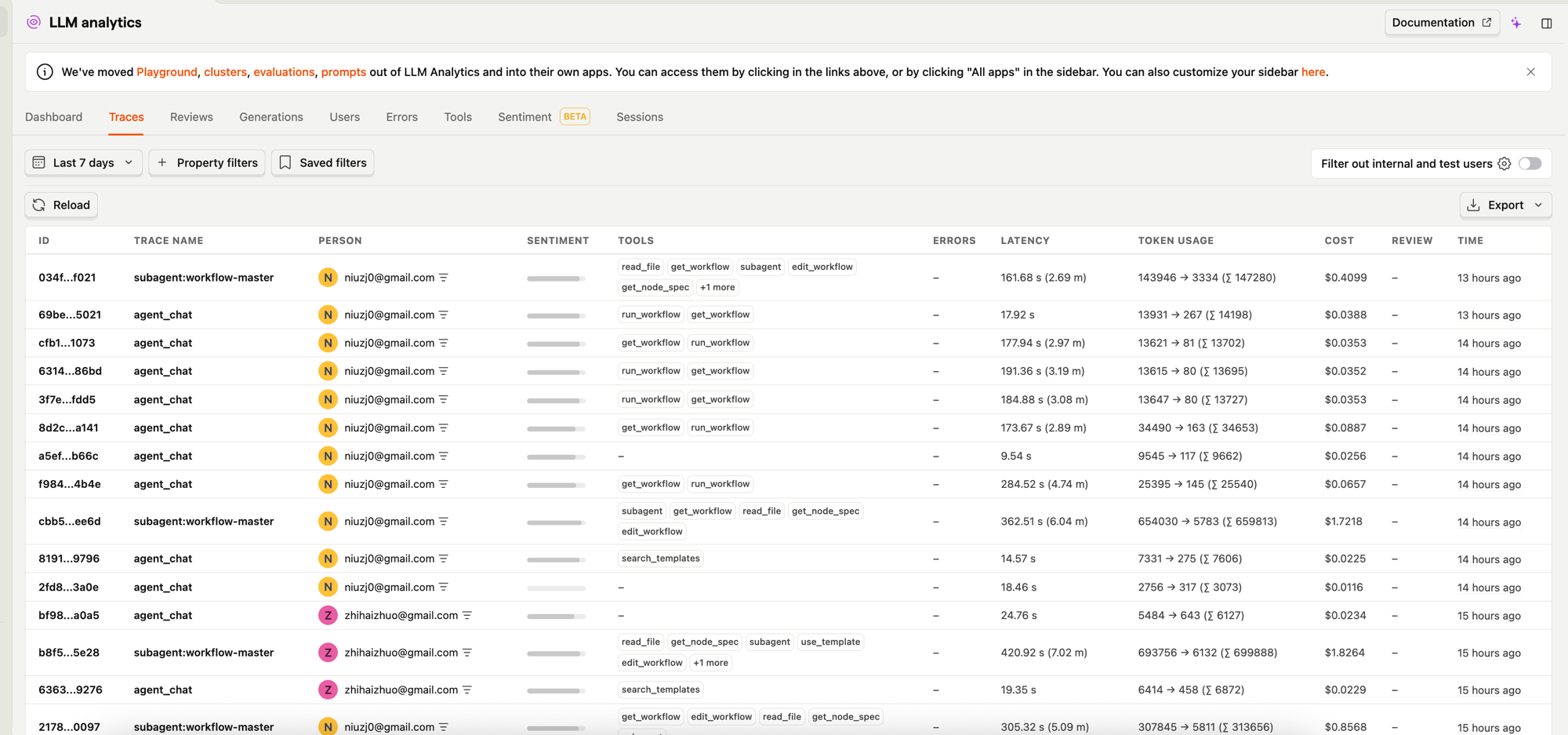
这个视图太有用了。之前用户说"回答慢",我完全不知道慢在哪。现在一看 trace,发现是某个 tool call 卡了 8 秒,一下就定位到问题了。
每次 LLM 调用的 input/output 都能展开看,包括传了什么 system prompt、模型返回了什么 tool call、token 用了多少。排查"回答不对"的问题,直接看 prompt 和 response 就行,不用再去翻日志了。
还有个 AI 助手能直接分析数据
PostHog 还有一个 AI 功能,可以直接用自然语言问它问题,它会根据你记录的数据给出分析:
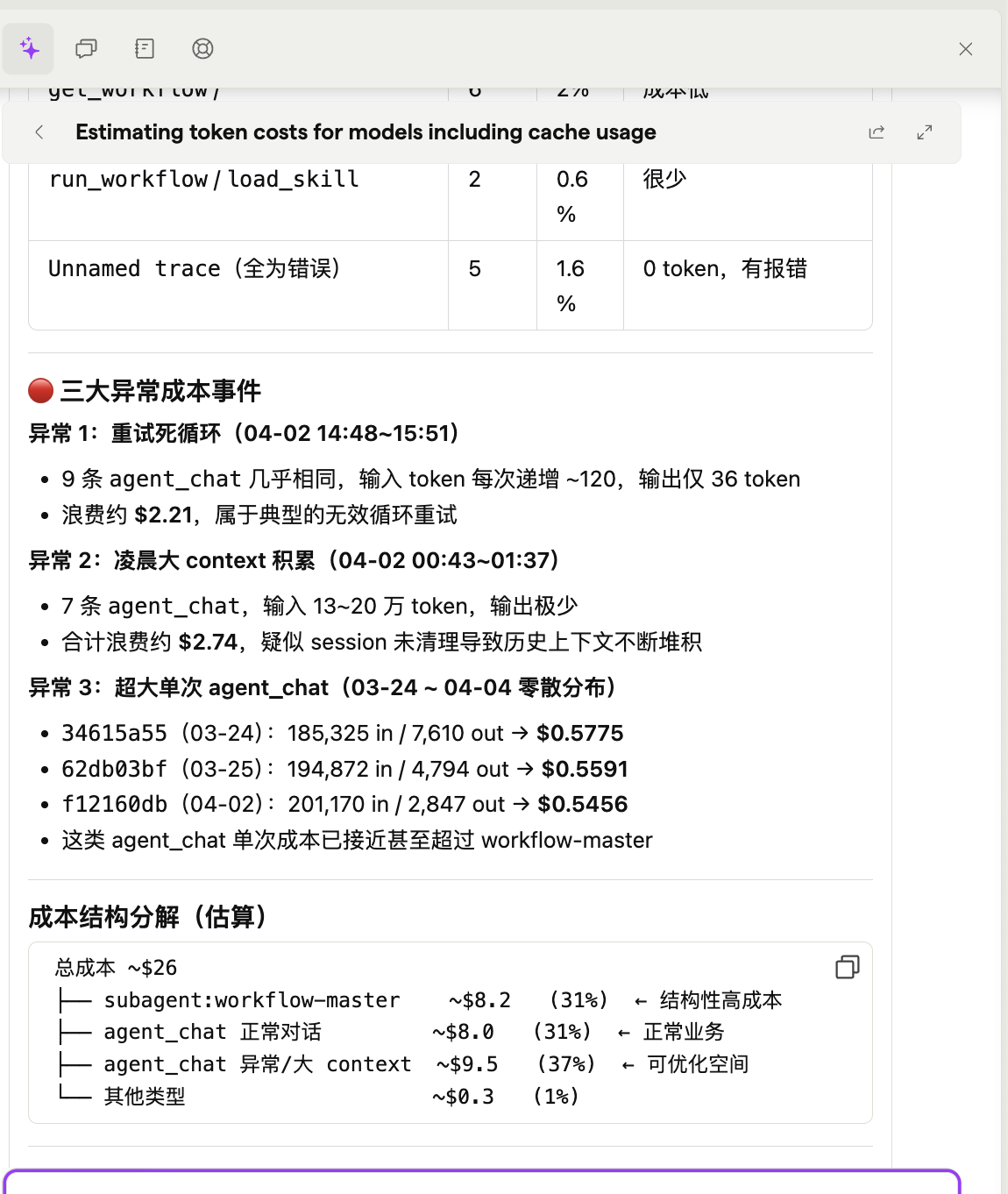
比如问"过去一周哪个 tool 的错误率最高"、“平均每次对话消耗多少 token”,它直接给你答案。省得自己写查询了。
成本监控:PostHog 怎么帮你算钱
接入之后我发现 PostHog 的 dashboard 上直接就有每次调用的 cost,不用自己算。研究了一下它的计算逻辑,还挺讲究的。
自动查表计算
PostHog 服务端维护了一个模型定价表(几百个模型,从 OpenRouter 数据自动更新)。你上报 $ai_model + $ai_provider + token 数,它自动查表算出美元成本。不需要你传价格,也不需要你维护定价表。
一次 API 调用的费用就是:
cost = input_tokens × input 单价 + output_tokens × output 单价
input_tokens 是你发给模型的所有内容(system prompt + 历史消息 + 工具定义 + 当前用户消息),output_tokens 是模型回复的内容(文本 + tool calls)。
别忘了上报 cached tokens
这里有个容易踩的坑。Agent 多轮对话每次调用都要把历史消息全部重新发一遍,第 10 轮对话的 input 里包含了前 9 轮的所有内容。OpenAI 的 prompt caching 是自动的,前缀匹配的部分会命中缓存,而 cached tokens 的单价比全价便宜很多。
拿 gpt-4.1 举例:
| 类型 | 单价 (per 1M tokens) |
|---|---|
| Input(全价) | $2.00 |
| Cached Input | $0.50 |
| Output | $8.00 |
如果你不上报 $ai_cache_read_input_tokens,PostHog 会把所有 input tokens 都按全价算,cost 会比实际账单高不少。
OpenAI 的 cached tokens 从 API 响应里取:
cached = 0
if usage.prompt_tokens_details:
cached = usage.prompt_tokens_details.cached_tokens or 0
上报后 PostHog 会自动拆分计算:cached 部分按折扣价,非 cached 部分按全价。不同 provider 的折扣不同,PostHog 内部都有处理(OpenAI cached 按 50%,Anthropic cache read 按 10%)。
三种定价模式
PostHog 支持三种方式,按优先级:
- 直传价格 — 发
$ai_input_cost_usd+$ai_output_cost_usd,PostHog 直接用,跳过计算。适合自定义模型或 tool 调用计费 - 自定义单价 — 发
$ai_input_token_price+$ai_output_token_price,PostHog 乘 token 数 - 自动查表 — 只发 token 数 + model 名,PostHog 查内置定价表(推荐,主流模型都支持)
如果你有付费的 tool 调用(比如搜索 API),可以用模式 1,发一个 $ai 事件直接传入价格,这样 tool 的费用也会汇总到 trace 的总 cost 里。
顺便说下 OpenAI 定价页上几个容易混淆的概念
Short context vs Long context — 不是"短对话/长对话",是按单次请求的总 token 数区分的。超过 128K tokens 的请求按 Long context 价格算(通常是 Short 的两倍)。Agent 多轮对话累积下来很容易超 128K。
Standard / Batch / Flex — 是不同的调用模式。Standard 就是正常的实时 API 调用,Batch 是批量异步处理(24 小时内返回,半价),Flex 介于两者之间。Agent 场景需要实时交互,用的都是 Standard。
几个实践建议
用了一段时间,总结几点:
1. 用 contextvars 传递 trace_id
Agent 的调用链是异步的,trace_id 需要在整个调用链里传递。用 Python 的 contextvars 最干净:
from contextvars import ContextVar
_posthog_ctx: ContextVar[PostHogContext] = ContextVar("posthog_ctx")
# 请求入口设置
ctx = PostHogContext(trace_id=uuid4().hex, distinct_id=user_id)
token = _posthog_ctx.set(ctx)
# 任何地方都能拿到
ctx = _posthog_ctx.get()
2. 大内容要截断
LLM 的 input/output 可能很大,特别是带图片或长文档的场景。上报前做截断,不然 PostHog 的事件会很臃肿:
# 单条消息限制 8KB,tool call 参数限制 4KB
content = content[:8192] if len(content) > 8192 else content
3. 加个隐私开关
如果你的 Agent 处理敏感数据,加一个 privacy mode,开启后只上报 token 数量和耗时,不上报具体的 prompt 和 response 内容。
4. 上报逻辑不要阻塞主流程
所有 PostHog 的 capture 调用都应该是 fire-and-forget 的。PostHog 的 Python SDK 本身就是异步批量发送的,但你自己的封装逻辑也要注意别 await 不必要的东西。
如果你也在做 Agent 开发,推荐试试 PostHog 的 LLM Analytics,接入成本很低,但能省掉大量排查问题的时间。